![Аватар сообщества AMAZON [новости]](/uploads/community/2/5b1b15e0-1cfd-4b12-8b0b-c041d6ef4d4f.jpg)
Сервис параллельных вычислений AWS теперь доступен всем и призван ускорить научные открытия

Сервис параллельных вычислений AWS теперь доступен всем и призван ускорить научные открытия. Amazon Web Services, Inc. (AWS), компания Amazon.com, Inc. (NASDAQ: AMZN), сегодня объявила о выпуске AWS Parallel Computing Service, нового управляемого сервиса, который помогает клиентам легко настраивать и управлять кластерами высокопроизводительных вычислений (HPC), чтобы они могли выполнять научные и инженерные рабочие нагрузки практически в любом масштабе на AWS. Сервис упрощает для системных администраторов создание кластеров с использованием экземпляров Amazon Elastic Compute Cloud (Amazon EC2), сетей с низкой задержкой и хранилища, оптимизированного для рабочих нагрузок HPC. С помощью AWS Parallel Computing Service ученые и инженеры могут быстро масштабировать моделирование для проверки моделей и проектов, в то время как системные администраторы и интеграторы могут создавать и поддерживать кластеры HPC на AWS с помощью Slurm, самого популярного менеджера рабочих нагрузок HPC с открытым исходным кодом. Этот сервис ускоряет инновации в таких областях, как быстрое открытие лекарств, раскрытие геномных идей, создание инженерных проектов, запуск погодных приложений и построение научных и инженерных моделей. AWS имеет историю инноваций в поддержке рабочих нагрузок HPC. Эта история включает в себя такие релизы, как инструментарий оркестровки кластеров с открытым исходным кодом AWS ParallelCluster, полностью управляемый сервис пакетных вычислений AWS Batch, сетевой адаптер Elastic Fabric с низкой задержкой, высокопроизводительное хранилище Amazon FSx для Lustre и выделенные вычислительные экземпляры HPC на базе AMD, Intel и Graviton, причем последние обеспечивают до 65% лучшее соотношение цены и производительности по сравнению с сопоставимыми оптимизированными для вычислений экземплярами на базе x86. Тысячи клиентов из самых разных отраслей перенесли свои рабочие нагрузки HPC в AWS, чтобы ускорить открытие лекарств, раскрыть геномные идеи, максимизировать энергетические ресурсы и развернуть суперкомпьютеры с миллионами ядер. Сегодня AWS продолжает наши инновации в HPC, выпуская полностью управляемый и комплексный сервис HPC, который устраняет недифференцированную тяжелую работу по созданию и управлению кластерами HPC. AWS Parallel Computing Service — это новый управляемый сервис, который помогает клиентам легко настраивать и управлять HPC, чтобы они могли выполнять научные и инженерные рабочие нагрузки практически в любом масштабе на AWS. С AWS Parallel Computing Service системные администраторы могут использовать знакомые инструменты, включая AWS Management Console, CLI и SDK, для развертывания управляемой среды Slurm. AWS Parallel Computing Service построен на основе открытых исходных кодов, которые клиенты знают и с которыми имеют опыт, и предоставляет управляемый опыт Slurm с надежностью и доступностью AWS. AWS Parallel Computing Service значительно снижает операционную нагрузку по управлению кластером и регулярно предоставляет новые возможности и исправления с помощью обновлений управляемых сервисов с минимальным или нулевым временем простоя, устраняя необходимость применять ручные исправления и перестраивать кластеры для получения обновлений функций. Высокодоступные API также помогают разработчикам и независимым поставщикам программного обеспечения создавать комплексные решения HPC поверх AWS, чтобы они могли сосредоточиться на предоставлении дополнительных функций своим пользователям и клиентам, а не беспокоиться об управлении инфраструктурой. AWS Parallel Computing Service позволяет клиентам всех размеров (например, стартапам, предприятиям или национальным лабораториям) легко создавать и управлять кластерами HPC с масштабируемостью, надежностью и безопасностью AWS. Это означает, что ученые и инженеры, использующие Slurm, могут легко переносить свои существующие локальные рабочие процессы в AWS без их перепроектирования, предоставляя ученым и инженерам доступ к облачной инфраструктуре, которая масштабируется автоматически. А администраторы, которые хотят разблокировать ограничения емкости или возможностей для своих конечных пользователей, могут разворачивать кластеры всего за несколько минут, а не месяцев, чтобы запускать свои симуляции для решения самых сложных мировых проблем. «Разработка лекарства от катастрофической болезни, проектирование новых материалов, развитие возобновляемой энергии и революция в транспорте — это проблемы, которые мы просто не можем позволить себе отложить в сторону», — сказал Ян Колле, директор по передовым вычислениям и моделированию в AWS. «Управление рабочими нагрузками HPC, особенно самыми сложными и сложными экстремально масштабными рабочими нагрузками, — это необычайно сложно. Наша цель состоит в том, чтобы каждый ученый и инженер, использующий AWS Parallel Computing Service, независимо от размера организации, был самым продуктивным человеком в своей области, поскольку у них есть те же самые высокоуровневые возможности HPC, что и у крупных предприятий, для решения самых сложных задач в мире, в любое время и в любом масштабе». Чтобы начать работу, системные администраторы используют AWS Management Console для безопасного развертывания кластера Slurm и выполнения заданий всего за несколько щелчков мыши по сравнению с ручной оркестровкой сегодня. Благодаря поддержке CloudFormation, которая появится в ближайшее время, клиенты смогут создавать и развертывать кластеры HPC с использованием инфраструктуры как кода. AWS Parallel Computing Service теперь доступен в следующих регионах: Восток США (Огайо), Восток США (Сев. Вирджиния), Запад США (Орегон), Европа (Франкфурт), Европа (Стокгольм), Европа (Ирландия), Азиатско-Тихоокеанский регион (Сидней), Азиатско-Тихоокеанский регион (Сингапур), Азиатско-Тихоокеанский регион (Токио). Marvel Fusion — это немецкий стартап в области термоядерной энергетики, который стремится создать неограниченную энергию с нулевым уровнем выбросов. «Мы рады, что AWS Parallel Computing Service предоставит высокодоступные и простые в обновлении возможности управления кластерами HPC», — сказал Мориц фон дер Линден, генеральный директор Marvel Fusion. «Это позволит нашим ученым и ИТ-специалистам воспользоваться новейшими возможностями AWS Parallel Computing Service за считанные часы, вместо недель планирования и накладных расходов, которые требовались ранее». Maxar Intelligence предоставляет безопасные и точные геопространственные данные, позволяя государственным и коммерческим клиентам отслеживать, понимать и ориентироваться на нашей меняющейся планете. «Как давний пользователь решений AWS HPC, мы были рады протестировать сервисно-ориентированный подход от AWS Parallel Computing Service», — сказал Трэвис Хартман, директор по погоде и климату в Maxar Intelligence. «Мы обнаружили большой потенциал для AWS Parallel Computing Service в плане обеспечения лучшей видимости кластеров, предоставления вычислений и интеграции сервисов на платформе WeatherDesk от Maxar Intelligence, что позволило бы команде сделать их чувствительные ко времени HPC-кластеры более устойчивыми и простыми в управлении». RONIN — австралийская компания-разработчик программного обеспечения, чей флагманский сервис HPC предоставляет простой, интуитивно понятный веб-интерфейс для исследователей и ученых из ведущих академических и исследовательских институтов для легкого запуска моделирования HPC на AWS. «Демократизация HPC в облаке путем упрощения пользовательского опыта для исследователей — наша ключевая миссия», — сказал Натан Олбрайтон, генеральный директор и основатель RONIN. «Внедрение AWS Parallel Computing Service значительно упрощает нашу возможность создания и эксплуатации сред HPC с использованием API и расширяет возможности HPC, которые мы предлагаем нашим клиентам». Национальная лаборатория возобновляемой энергии Министерства энергетики США (NREL) является ведущим учреждением, сосредоточенным на исследованиях, инновациях и стратегических партнерствах для предоставления решений для экономики чистой энергии. «Стремление к научным открытиям сопряжено со значительными накладными расходами, связанными с поддержанием высокопроизводительной вычислительной инфраструктуры», — сказал Майкл Бартлетт, архитектор облачных вычислений в группе Advance Computing Operations в NREL. «AWS Parallel Computing Service имеет потенциал для повышения эффективности наших исследований за счет снижения этих накладных расходов с помощью функций автоматического обновления и управления наблюдаемостью. В частности, новые возможности для автоматического масштабирования и обработки высокопроизводительных вычислительных задач позволят нам эффективно обрабатывать большие наборы данных и сложные симуляции, гарантируя, что наши ученые смогут расставить приоритеты в решении высокоприоритетных проблем». Источник: www.businesswire.com
Пост взят с международного финтех-медиа ресурса
ДЛЯ ЛЮДЕЙ
![Аватар сообщества GOLDMAN SACHS [новости]](/uploads/community/1/ff5c3044-1b80-4619-87d5-89cda4894b30.jpg)

![Аватар сообщества JPMORGAN [новости]](/uploads/community/1/ce52cd1a-4068-42b6-9dfb-5a9fcd7de8f3.jpg)

![Аватар сообщества BANK OF AMERICA [новости]](/uploads/community/1/1712239225_09cf6a11ef0125d9386dd0099d5b9fe0.jpg)

![Аватар сообщества INTEL [новости]](/uploads/community/1/9163d0cd-bb51-41d2-a061-110ccef0fb3b.jpg)

![Аватар сообщества WALT DISNEY [DIS] [анализ]](/uploads/community/3/db7293d6-9f77-4523-8833-20bb033183fe.jpg)

![Аватар сообщества MICROSOFT [новости]](/uploads/community/1/1712244752_f1077befa4c2ba0b9a839842f135968b.jpg)
![Аватар сообщества ALPHABET [новости]](/uploads/community/2/1712310220_ff8cf36099c4dff41c9a3ece1045d01c.jpg)


![Аватар сообщества IBM [новости]](/uploads/community/4/91864cab-6c2c-4724-9361-7351055d7e58.jpg)



![Аватар сообщества BOOKING [новости]](/uploads/community/3/10ac0068-9704-4b0d-8fa8-37ea6f2e9cdb.jpg)

![Аватар сообщества APPLE [новости]](/uploads/community/2/1651f5f9-00e6-46d0-90ec-1b8c7dd0adcd.jpg)

![Аватар сообщества MCDONALD'S [новости]](/uploads/community/4/ffc93c60-b81b-4fe9-9ca2-1f583373866d.jpg)


![Аватар сообщества AMD [новости]](/uploads/community/1/d92e339e-b35e-4b0f-ba72-ede6bc3fcf63.jpg)

![Аватар сообщества STRATEGY [новости]](/uploads/community/5/ed1ed55f-f7cc-43b9-be84-d64f3fb01d12.jpg)

![Аватар сообщества PEPSICO [новости]](/uploads/community/4/1712495283_40fa4822575a0c08d3a0d7aec0d06c8c.jpg)

![Аватар сообщества NIKE [новости]](/uploads/community/4/297f9872-1934-43a7-957f-5a0dd2739eba.jpg)


![Аватар сообщества BERKSHIRE HATHAWAY [новости]](/uploads/community/10/7e54b741-708c-42d7-ae4a-6641b2044f74.jpg)
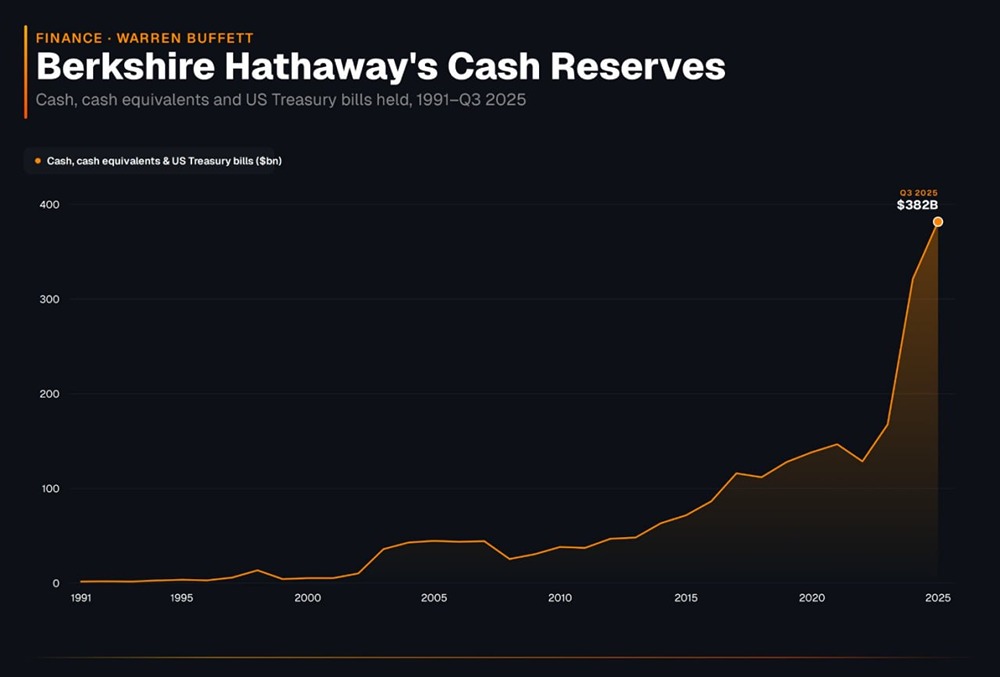

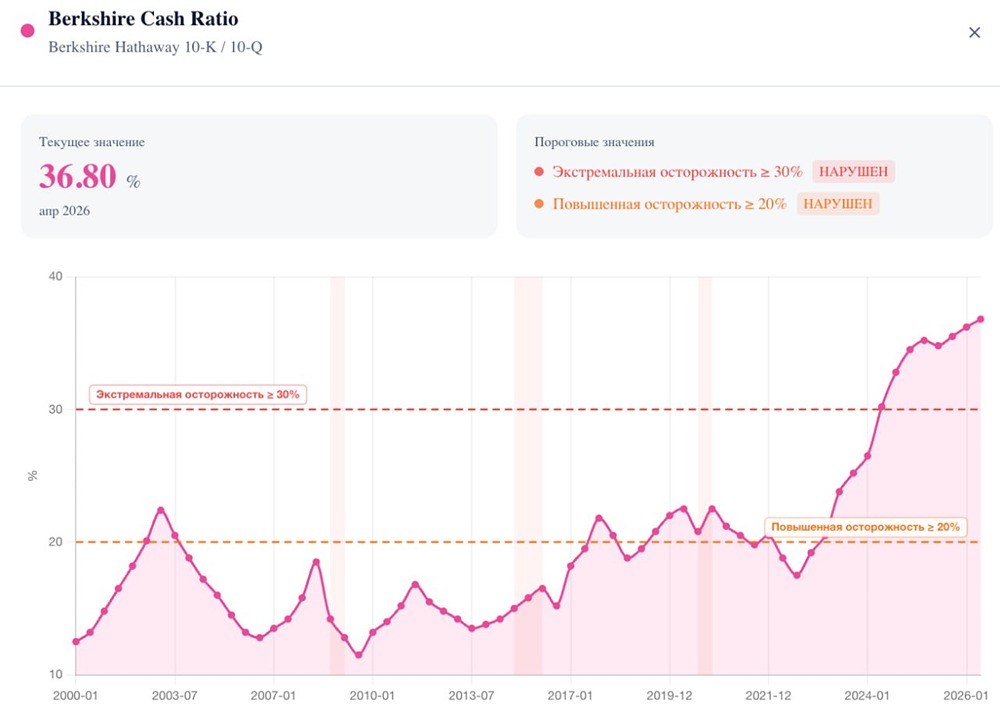

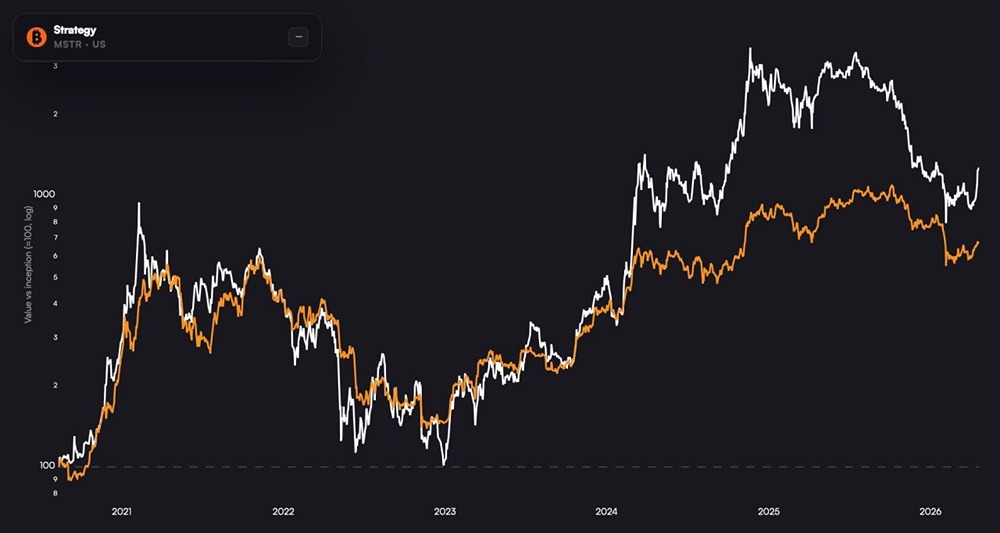
![Аватар сообщества STRATEGY [MSTR] [анализ]](/uploads/community/5/2c11d846-91a8-4462-b768-3da3b48f1049.jpg)
![Аватар сообщества STARBUCKS [новости]](/uploads/community/4/ed32d594-7f54-45a5-b07c-6af5f963258b.jpg)

![Аватар сообщества TESLA [новости]](/uploads/community/2/66ea8c2b-c1b2-4605-bc1a-9185b2727ad9.jpg)

![Аватар сообщества VISA [новости]](/uploads/community/3/86208ff5-1668-4a4d-9f38-1d5a6a2cd64b.jpg)

![Аватар сообщества MORGAN STANLEY [новости]](/uploads/community/10/76330125-47dd-4473-81c7-95886ad1fb20.jpg)

![Аватар сообщества BOEING [новости]](/uploads/community/2/e753d30c-7fcf-4cda-92b4-6f792168f040.jpg)


![Аватар сообщества FORD [новости]](/uploads/community/2/59785168-9b8d-4bd1-82b4-73154ba3aa0a.jpg)

![Аватар сообщества DOMINO'S PIZZA [новости]](/uploads/community/8/7cc111a5-e82b-40fb-8fa4-e96a803ff97d.jpg)


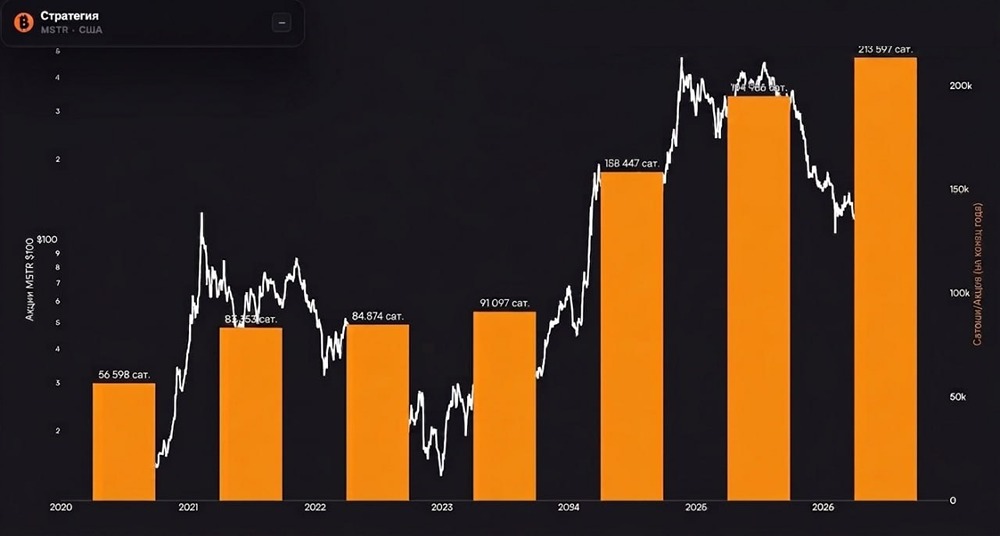
![Аватар сообщества 3M [новости]](/uploads/community/9/587ddb52-4375-4b03-8530-afb3d3cf91a4.jpg)

![Аватар сообщества ADOBE [новости]](/uploads/community/2/1e138d44-8ee7-4551-abe5-f5b2258eb927.jpg)


![Аватар сообщества GENERAL MOTORS [новости]](/uploads/community/2/1712337275_fa0d472d3af880017f2137eea0bd8529.jpg)