![Аватар сообщества ALPHABET [новости]](/uploads/community/2/1712310220_ff8cf36099c4dff41c9a3ece1045d01c.jpg)
Новости по акциям компании GOOGLE (ALPHABET)

Новость: негативная. Baidu блокирует сбор контента Google и Bing на фоне спроса на данные, используемые в проектах ИИ. Китайский поисковый гигант Baidu , по всей видимости, начал блокировать поисковым системам Google (Alphabet) и Bing (Microsoft) возможность извлекать контент из сервиса этой китайской компании, работающего в стиле Wikipedia, говорится в исследовании Post. Недавнее обновление файла robots.txt компании Baidu Baike — файла, сообщающего поисковым роботам, к каким унифицированным указателям ресурсов, обычно называемым веб-адресами, можно получить доступ с сайта, — полностью заблокировало возможность роботов Googlebot и Bingbot индексировать контент с китайской платформы. Это обновление, по-видимому, было сделано где-то 8 августа, согласно записям в интернет-архиве Wayback Machine. Оно также показало, что ранее в тот же день Baidu Baike все еще позволял Google и Bing просматривать и индексировать свой онлайн-репозиторий из почти 30 миллионов записей, при этом только часть его веб-сайта была обозначена как закрытая. У вас есть вопросы о самых важных темах и тенденциях со всего мира? Получите ответы с помощью SCMP Knowledge , нашей новой платформы курируемого контента с пояснениями, часто задаваемыми вопросами, анализами и инфографикой, предоставленными вам нашей отмеченной наградами командой. Эта инициатива свидетельствует о возросших усилиях базирующейся в Пекине компании Baidu по защите своих онлайн-активов, поскольку возрос спрос на огромные массивы данных для обучения и создания моделей и приложений искусственного интеллекта (ИИ). Это последовало за шагом американской платформы социальных новостей и форума Reddit в июле, когда она заблокировала различным поисковым системам, кроме Google, индексацию своих онлайн-постов и обсуждений. У Google есть многомиллионная сделка с Reddit, которая дает ей право собирать данные с платформы социальных сетей для обучения своих служб ИИ. По данным Bloomberg, в прошлом году даже Microsoft пригрозила прекратить доступ к своим данным интернет-поиска, которые она лицензирует конкурирующим операторам поисковых систем, если они не прекратят использовать их в качестве основы для своих чат-ботов и других сервисов генеративного искусственного интеллекта (GenAI). Для сравнения, китайская версия онлайн-энциклопедии Wikipedia на сегодняшний день содержит 1,43 миллиона записей, которые доступны поисковым роботам. После обновления файла robots.txt компанией Baidu Baike исследование Google и Bing, проведенное Post в пятницу, выявило, что многие записи (вероятно, из старого кэшированного контента) из сервиса в стиле Википедии по-прежнему появляются в результатах поиска на американских платформах. Представители Baidu, Google и Microsoft в пятницу не отреагировали на просьбы прокомментировать ситуацию. Более чем через два года после новаторского запуска OpenAI's ЧатGPT многие крупные разработчики искусственного интеллекта по всему миру заключают соглашения с издателями контента для доступа к качественному контенту для своих проектов GenAI. GenAI относится к алгоритмам и сервисам, таким как ChatGPT, которые используются для создания нового контента, включая аудио, код, изображения, текст, симуляции и видео. Например, в июне компания OpenAI заключила соглашение с американским новостным журналом Time, которое дает ей доступ ко всему архивному контенту за более чем 100-летнюю историю издания. Источник: www.scmp.com
Пост взят с международного финтех-медиа ресурса
ДЛЯ ЛЮДЕЙ
![Аватар сообщества GOLDMAN SACHS [новости]](/uploads/community/1/ff5c3044-1b80-4619-87d5-89cda4894b30.jpg)

![Аватар сообщества JPMORGAN [новости]](/uploads/community/1/ce52cd1a-4068-42b6-9dfb-5a9fcd7de8f3.jpg)

![Аватар сообщества BANK OF AMERICA [новости]](/uploads/community/1/1712239225_09cf6a11ef0125d9386dd0099d5b9fe0.jpg)

![Аватар сообщества INTEL [новости]](/uploads/community/1/9163d0cd-bb51-41d2-a061-110ccef0fb3b.jpg)

![Аватар сообщества WALT DISNEY [DIS] [анализ]](/uploads/community/3/db7293d6-9f77-4523-8833-20bb033183fe.jpg)

![Аватар сообщества MICROSOFT [новости]](/uploads/community/1/1712244752_f1077befa4c2ba0b9a839842f135968b.jpg)


![Аватар сообщества IBM [новости]](/uploads/community/4/91864cab-6c2c-4724-9361-7351055d7e58.jpg)



![Аватар сообщества BOOKING [новости]](/uploads/community/3/10ac0068-9704-4b0d-8fa8-37ea6f2e9cdb.jpg)

![Аватар сообщества APPLE [новости]](/uploads/community/2/1651f5f9-00e6-46d0-90ec-1b8c7dd0adcd.jpg)

![Аватар сообщества TESLA [новости]](/uploads/community/2/66ea8c2b-c1b2-4605-bc1a-9185b2727ad9.jpg)

![Аватар сообщества MCDONALD'S [новости]](/uploads/community/4/ffc93c60-b81b-4fe9-9ca2-1f583373866d.jpg)


![Аватар сообщества AMD [новости]](/uploads/community/1/d92e339e-b35e-4b0f-ba72-ede6bc3fcf63.jpg)

![Аватар сообщества STRATEGY [новости]](/uploads/community/5/ed1ed55f-f7cc-43b9-be84-d64f3fb01d12.jpg)
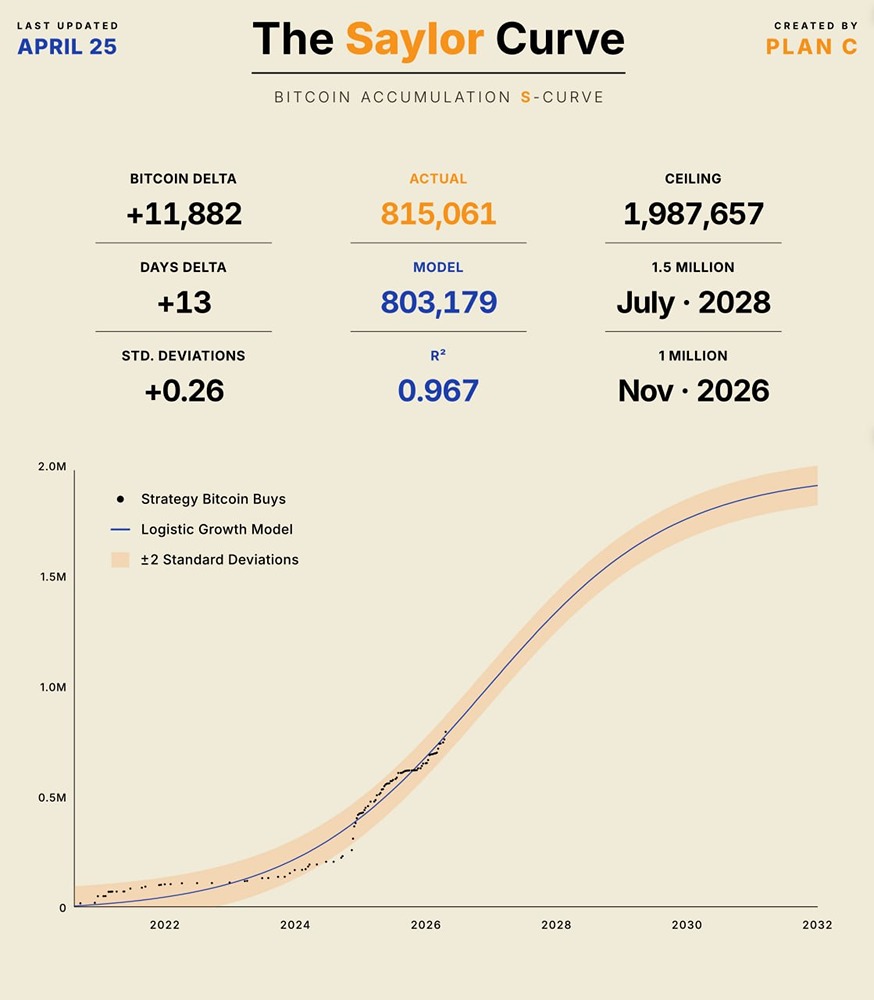

![Аватар сообщества MORGAN STANLEY [новости]](/uploads/community/10/76330125-47dd-4473-81c7-95886ad1fb20.jpg)

![Аватар сообщества VISA [новости]](/uploads/community/3/86208ff5-1668-4a4d-9f38-1d5a6a2cd64b.jpg)

![Аватар сообщества BOEING [новости]](/uploads/community/2/e753d30c-7fcf-4cda-92b4-6f792168f040.jpg)


![Аватар сообщества FORD [новости]](/uploads/community/2/59785168-9b8d-4bd1-82b4-73154ba3aa0a.jpg)


![Аватар сообщества PEPSICO [новости]](/uploads/community/4/1712495283_40fa4822575a0c08d3a0d7aec0d06c8c.jpg)


![Аватар сообщества NIKE [новости]](/uploads/community/4/297f9872-1934-43a7-957f-5a0dd2739eba.jpg)

![Аватар сообщества BERKSHIRE HATHAWAY [новости]](/uploads/community/10/7e54b741-708c-42d7-ae4a-6641b2044f74.jpg)
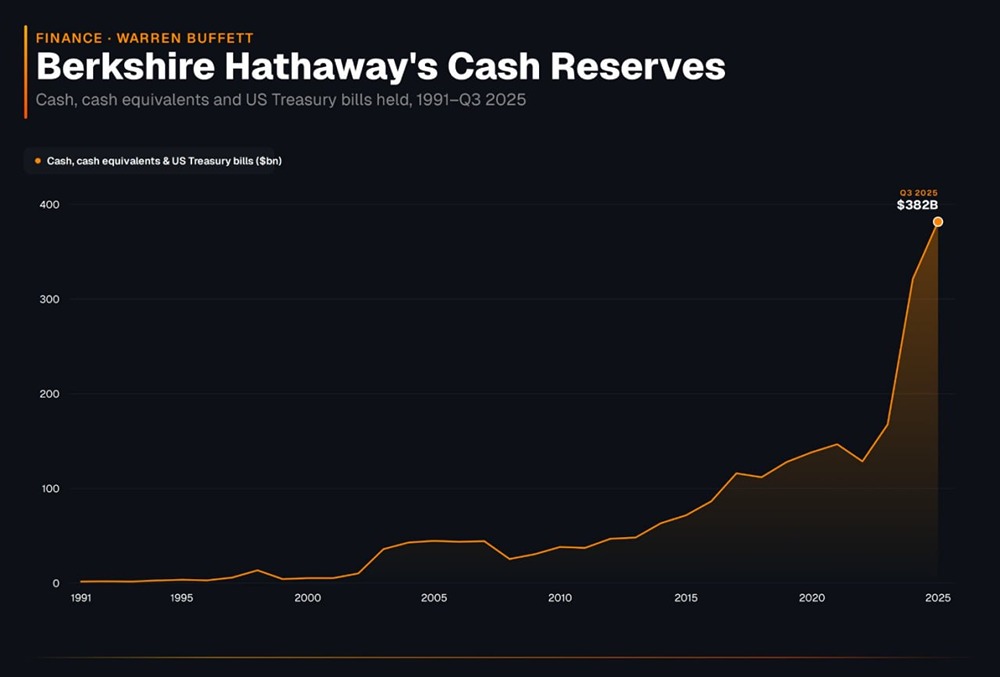
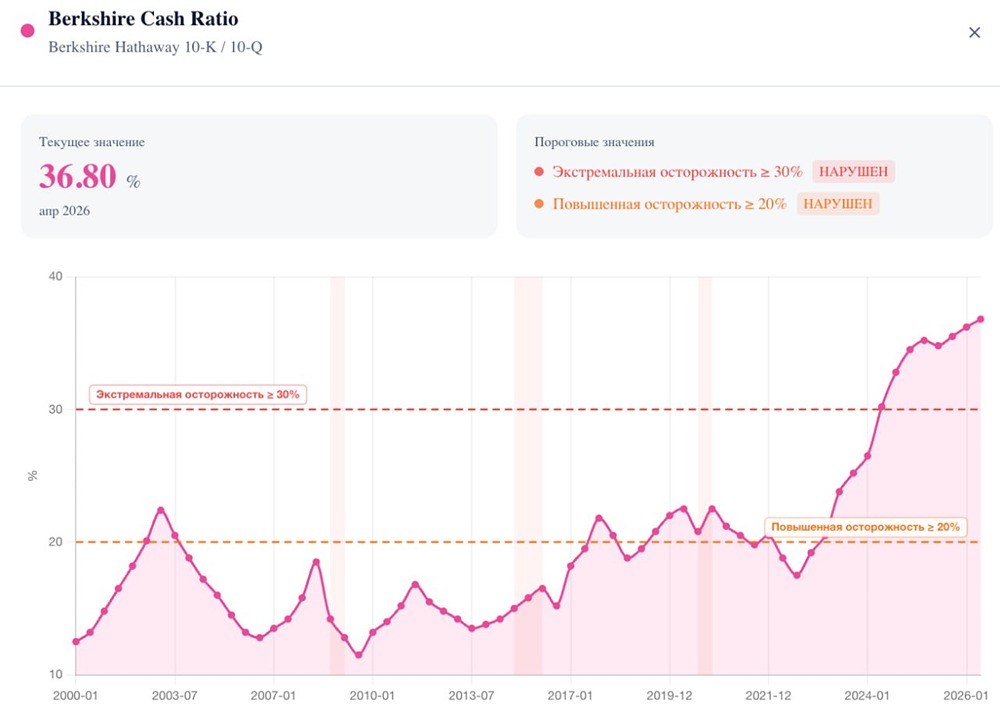
![Аватар сообщества STRATEGY [MSTR] [анализ]](/uploads/community/5/2c11d846-91a8-4462-b768-3da3b48f1049.jpg)
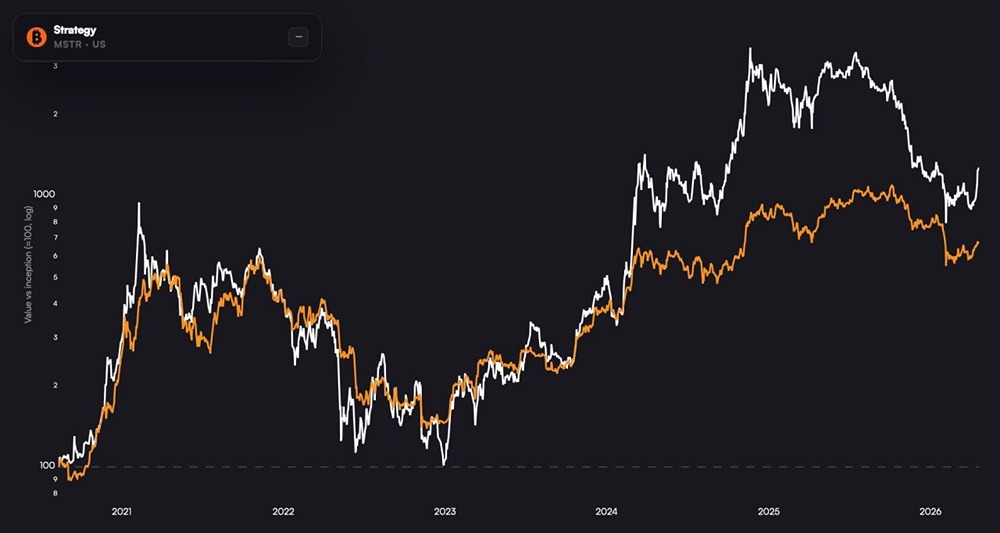
![Аватар сообщества DOMINO'S PIZZA [новости]](/uploads/community/8/7cc111a5-e82b-40fb-8fa4-e96a803ff97d.jpg)

![Аватар сообщества GENERAL MOTORS [новости]](/uploads/community/2/1712337275_fa0d472d3af880017f2137eea0bd8529.jpg)

![Аватар сообщества ADOBE [новости]](/uploads/community/2/1e138d44-8ee7-4551-abe5-f5b2258eb927.jpg)


![Аватар сообщества MASTERCARD [новости]](/uploads/community/3/1867dd73-3f99-4da8-a5e7-fcb370911df1.jpg)




![Аватар сообщества FEDEX [новости]](/uploads/community/2/f95e1a48-7cbc-447d-9c8e-ceba54fce4fa.jpg)