![Аватар сообщества AMAZON [новости]](/uploads/community/2/5b1b15e0-1cfd-4b12-8b0b-c041d6ef4d4f.jpg)
Новости по акциям компании AMAZON (amazon.com)

Новость: положительная. Amazon хочет размещать собственные генеративные модели искусственного интеллекта компаний. AWS, подразделение облачных вычислений Amazon, хочет стать местом , где компании размещают и настраивают свои собственные генеративные модели искусственного интеллекта. Сегодня AWS объявила о запуске импорта пользовательских моделей (в предварительной версии), новой функции в Bedrock, пакете генеративных сервисов AWS для предприятий, ориентированном на ИИ. Эта функция позволяет организациям импортировать свои собственные генеративные модели искусственного интеллекта и получать к ним доступ в виде полностью управляемых API. Запатентованные модели компаний после импорта получают выгоду от той же инфраструктуры, что и другие генеративные модели искусственного интеллекта в библиотеке Bedrock (например, Llama 3 от Meta или Claude 3 от Anthropic). Они также получат инструменты для расширения своих знаний, их тонкой настройки и внедрения мер защиты, позволяющих смягчить свои предубеждения. «Были клиенты AWS, которые настраивали или создавали свои собственные модели за пределами Bedrock, используя другие инструменты», — рассказал TechCrunch Васи Филомин, вице-президент по генеративному искусственному интеллекту в AWS. «Эта возможность импорта пользовательских моделей позволяет им переносить свои собственные модели в Bedrock и видеть их рядом со всеми другими моделями, которые уже есть в Bedrock, а также использовать их во всех рабочих процессах, которые также уже есть в Bedrock." Импорт пользовательских моделей Согласно недавнему опросу , проведенному Cnvrg, дочерней компанией Intel, специализирующейся на искусственном интеллекте, большинство предприятий подходят к генеративному искусственному интеллекту, создавая свои собственные модели и доводя их до своих приложений. Согласно опросу, предприятия говорят, что они рассматривают инфраструктуру, включая инфраструктуру облачных вычислений, как самое большое препятствие для развертывания. С помощью импорта пользовательских моделей AWS стремится удовлетворить эту потребность, не отставая от конкурентов в облаке. (Генеральный директор Amazon Энди Джасси предсказал это в своем недавнем ежегодном письме акционерам.) В течение некоторого времени Vertex AI, аналог Bedrock от Google, позволял клиентам загружать генеративные модели ИИ, адаптировать их и обслуживать через API. Databricks также уже давно предоставляет наборы инструментов для размещения и настройки пользовательских моделей, включая недавно выпущенный собственный DBRX . На вопрос, что отличает Custom Model Import, Филомин ответил, что он — и, как следствие, Bedrock — предлагает более широкий спектр и глубину возможностей настройки модели, чем конкуренты, добавив, что «десятки тысяч» клиентов сегодня используют Bedrock. «Во-первых, Bedrock предлагает клиентам несколько способов работы с моделями обслуживания», — сказал Филомин. «Во-вторых, у нас есть целый ряд рабочих процессов вокруг этих моделей — и теперь клиенты могут стоять рядом со всеми другими моделями, которые у нас уже доступны. Ключевая вещь, которая нравится большинству людей в этой модели, — это возможность экспериментировать с несколькими различными моделями, используя одни и те же рабочие процессы, а затем фактически запускать их в производство из одного и того же места». Итак, каковы упомянутые варианты настройки модели? Филомин указывает на Guardrails, который позволяет пользователям Bedrock настраивать пороговые значения для фильтрации — или, по крайней мере, попыток фильтрации — выходных данных моделей на предмет таких вещей, как разжигание ненависти, насилие и личная личная или корпоративная информация. (Генераторные модели ИИ печально известныидущий сошедший с рельсоввпроблемные способы, включая утечку конфиденциальной информации; Модели AWS былине исключение.) Он также остановился на оценке модели — инструменте Bedrock, который клиенты могут использовать для проверки того, насколько хорошо модель (или несколько) работает по заданному набору критериев. И Guardrails, и Model Evaluation теперь общедоступны после предварительной версии, длившейся несколько месяцев. Я вынужден отметить, что импорт пользовательских моделей на данный момент поддерживает только три архитектуры моделей: модели Flan-T5 от Hugging Face, Llama от Meta и модели Mistral. Кроме того, Vertex AI и другие конкурирующие сервисы Bedrock, включая инструменты разработки искусственного интеллекта Microsoft в Azure, предлагают более или менее сопоставимые функции безопасности и оценки (см.Безопасность контента Azure AI,оценка модели в Vertex, и т. д.). Однако уникальной особенностью Bedrock является семейство генеративных моделей искусственного интеллекта AWS Titan. И одновременно с выпуском Custom Model Import на этом фронте произошло несколько примечательных событий. Модернизированные модели Титана Генератор изображений Титана, модель преобразования текста в изображение AWS, теперь общедоступна после запуска предварительной версии в ноябре прошлого года. Как и раньше, Titan Image Generator может создавать новые изображения из текстового описания или настраивать существующие изображения — например, заменять фон изображения, сохраняя при этом объекты на изображении. По сравнению с предварительной версией Titan Image Generator в GA может генерировать изображения с большей «креативностью», — сказал Филомин, не вдаваясь в подробности. (Ваше предположение о том, что это значит, так же хорошо, как и мое.) Я спросил Филомина, может ли он поделиться более подробной информацией о том, как обучался Titan Image Generator. Во время дебюта модели в ноябре прошлого года AWS не уточнила, какие именно данные она использовала при обучении Titan Image Generator. Лишь немногие поставщики охотно раскрывают такую информацию; они рассматривают данные тренировок как конкурентное преимущество и поэтому держат их и связанную с ними информацию при себе. Подробности данных обучения также являются потенциальным источником судебных исков, связанных с интеллектуальной собственностью, что является еще одним препятствием для раскрытия информации. В нескольких делах, проходящих через суды, отклоняются доводы продавцов о добросовестном использовании, утверждая, что инструменты преобразования текста в изображение копируют стили художников без явного разрешения художников и позволяют пользователям создавать новые произведения, напоминающие оригиналы художников, за которые художники не получают никаких прав. оплата. Филомин сказал мне только, что AWS использует комбинацию собственных и лицензионных данных. «У нас есть ряд собственных источников данных, но мы также лицензируем большое количество данных», — сказал он. « На самом деле мы платим владельцам авторских прав лицензионные сборы, чтобы иметь возможность использовать их данные, и у нас есть контракты с некоторыми из них». Это больше деталей, чем мы получили в ноябре. Но у меня такое ощущение, что ответ Филомина не удовлетворит всех, особенно создателей контента и специалистов по этике ИИ, выступающих за большую прозрачность в обучении генеративных моделей ИИ. Вместо прозрачности AWS заявляет, что продолжит предлагатьполитика возмещения убытковэто распространяется на клиентов в случае, если модель Titan, такая как Titan Image Generator, отрыгивает (т. е. выдает зеркальную копию) обучающий пример, потенциально защищенный авторским правом. (Некоторые конкуренты, в том числе Microsoft и Google, предлагают аналогичную политику в отношении своих моделей создания изображений.) Чтобы устранить еще одну серьезную этическую угрозу — дипфейки, — AWS заявляет, что изображения, созданные с помощью Titan Image Generator, как и во время предварительного просмотра, будут сопровождаться «защищенным от несанкционированного доступа» невидимым водяным знаком. Филомин говорит, что в общедоступной версии водяной знак стал более устойчивым к сжатию и другим изменениям и манипуляциям с изображениями. Переходя на менее противоречивую тему, я спросил Филомина, изучает ли AWS, как Google, OpenAI и другие, генерацию видео, учитывая ажиотаж вокруг этой технологии (и инвестиции в нее). Филомин не сказал, что AWS нет … но на большее он и намекать не стал. «Очевидно, что мы постоянно ищем, какие новые возможности хотят получить клиенты, и создание видео определенно всплывает в разговорах с клиентами», — сказал Филомин. «Я бы попросил вас оставаться с нами». В качестве последней новости, связанной с Titan, AWS выпустила второе поколение своей модели Titan Embeddings — Titan Text Embeddings V2. Эта модель преобразует текст в числовые представления, называемые встраиваниями, для расширения возможностей приложений поиска и персонализации. Модель Embeddings первого поколения тоже делала то же самое, но AWS утверждает, что Titan Text Embeddings V2 в целом более эффективен, экономичен и точен. «Модель Embeddings V2 сокращает общий объем памяти [необходимый для использования модели] почти в четыре раза, сохраняя при этом 97% точности», — заявил Филомин, — «превзойдя другие сопоставимые модели». Посмотрим, подтвердят ли это реальные испытания. Автор: Kyle Wiggers. Источник: www.techcrunch.com
Пост взят с международного финтех-медиа ресурса
ДЛЯ ЛЮДЕЙ
![Аватар сообщества TESLA [новости]](/uploads/community/2/66ea8c2b-c1b2-4605-bc1a-9185b2727ad9.jpg)

![Аватар сообщества VISA [новости]](/uploads/community/3/86208ff5-1668-4a4d-9f38-1d5a6a2cd64b.jpg)

![Аватар сообщества APPLE [новости]](/uploads/community/2/1651f5f9-00e6-46d0-90ec-1b8c7dd0adcd.jpg)


![Аватар сообщества MASTERCARD [новости]](/uploads/community/3/1867dd73-3f99-4da8-a5e7-fcb370911df1.jpg)

![Аватар сообщества FEDEX [новости]](/uploads/community/2/f95e1a48-7cbc-447d-9c8e-ceba54fce4fa.jpg)

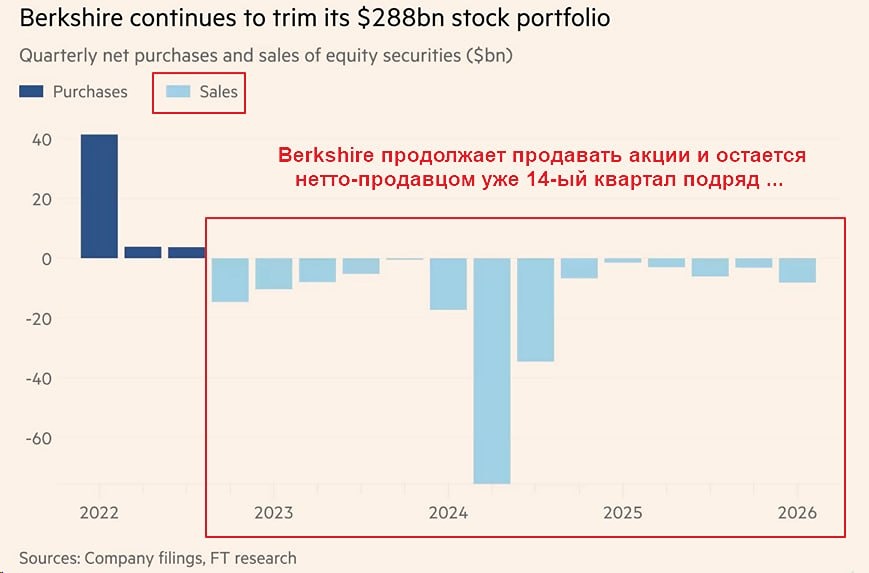
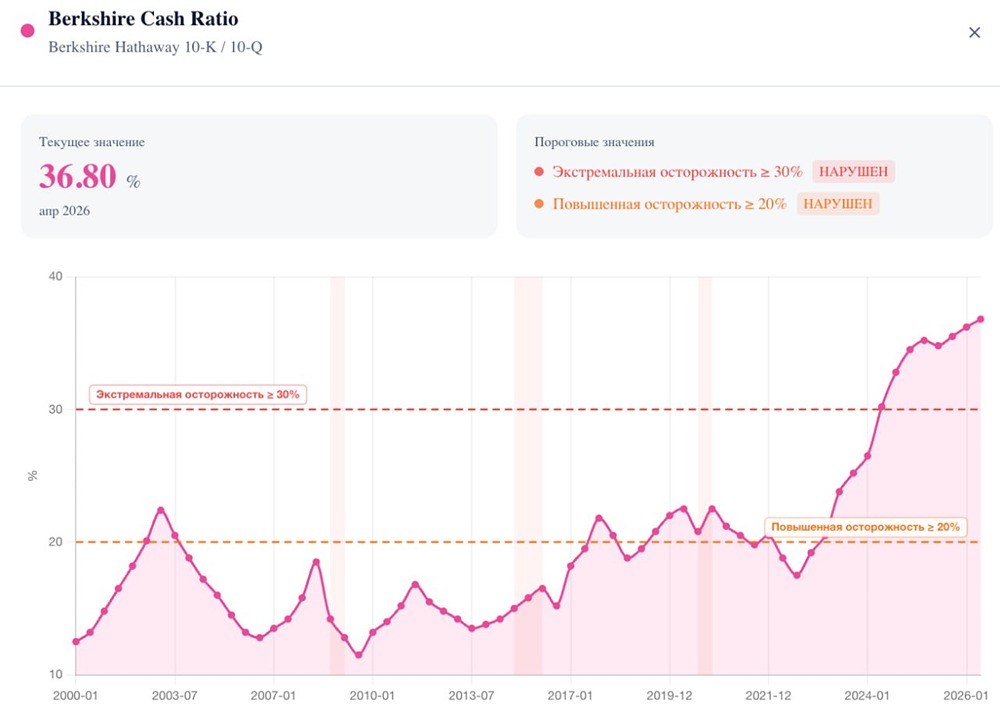
![Аватар сообщества BERKSHIRE HATHAWAY [новости]](/uploads/community/10/7e54b741-708c-42d7-ae4a-6641b2044f74.jpg)
![Аватар сообщества MORGAN STANLEY [новости]](/uploads/community/10/76330125-47dd-4473-81c7-95886ad1fb20.jpg)


![Аватар сообщества CHEVRON [новости]](/uploads/community/4/fd9f64cd-9735-4c6a-93ae-d356d9daf48d.jpg)



![Аватар сообщества ALPHABET [новости]](/uploads/community/2/1712310220_ff8cf36099c4dff41c9a3ece1045d01c.jpg)

![Аватар сообщества JOHNSON & JOHNSON [новости]](/uploads/community/3/79fc3a28-a17b-4e8d-b965-e42db9f2fe19.jpg)

![Аватар сообщества IBM [новости]](/uploads/community/4/91864cab-6c2c-4724-9361-7351055d7e58.jpg)

![Аватар сообщества BOOKING [новости]](/uploads/community/3/10ac0068-9704-4b0d-8fa8-37ea6f2e9cdb.jpg)

![Аватар сообщества JPMORGAN [новости]](/uploads/community/1/ce52cd1a-4068-42b6-9dfb-5a9fcd7de8f3.jpg)

![Аватар сообщества BOEING [новости]](/uploads/community/2/e753d30c-7fcf-4cda-92b4-6f792168f040.jpg)



![Аватар сообщества MICROSOFT [новости]](/uploads/community/1/1712244752_f1077befa4c2ba0b9a839842f135968b.jpg)

![Аватар сообщества FORD [новости]](/uploads/community/2/59785168-9b8d-4bd1-82b4-73154ba3aa0a.jpg)

![Аватар сообщества ADOBE [новости]](/uploads/community/2/1e138d44-8ee7-4551-abe5-f5b2258eb927.jpg)



![Аватар сообщества DOMINO'S PIZZA [новости]](/uploads/community/8/7cc111a5-e82b-40fb-8fa4-e96a803ff97d.jpg)

![Аватар сообщества INTEL [новости]](/uploads/community/1/9163d0cd-bb51-41d2-a061-110ccef0fb3b.jpg)




![Аватар сообщества EBAY [новости]](/uploads/community/8/9a4e81d8-2f6d-444b-86a2-44560f6e3182.jpg)


![Аватар сообщества GENERAL MOTORS [новости]](/uploads/community/2/1712337275_fa0d472d3af880017f2137eea0bd8529.jpg)

![Аватар сообщества AMD [новости]](/uploads/community/1/d92e339e-b35e-4b0f-ba72-ede6bc3fcf63.jpg)

![Аватар сообщества PEPSICO [новости]](/uploads/community/4/1712495283_40fa4822575a0c08d3a0d7aec0d06c8c.jpg)


![Аватар сообщества MCDONALD'S [новости]](/uploads/community/4/ffc93c60-b81b-4fe9-9ca2-1f583373866d.jpg)

![Аватар сообщества ORACLE [новости]](/uploads/community/3/1712398533_430f34c801de10b6cd641b1ddeba714a.jpg)








































