![Аватар сообщества ЯНДЕКС [новости]](/uploads/community/2/dca78d58-9d3f-48a0-8d3a-7bf714273ff3.jpg)
Новость по компании ЯНДЕКС

Новость: нейтральная. Нейросетям «Яндекса» не хватает текстов на экзотических языках. Это ухудшает качество работы ИИ, но русские и английские модели это не затронет. Разработчики моделей машинного обучения (LLM) сталкиваются с дефицитом текстов на различных языках для их обучения, заявил директор по развитию технологий ИИ «Яндекса» Александр Крайнов 18 апреля во время выступления на форуме Data Fusion. «Для обучения языковых моделей нужно много хороших текстов, и выясняется, что их просто нет физически, – сетует Крайнов. – На английском языке их много, возможно даже избыточно. На русском языке мы собираем все, до чего можно дотянуться, и как-то более-менее хватает для создания качественных языковых моделей, но избытка нет. А если мы возьмем множество других языков, которые менее распространены в интернете, например данные для узбекского, таджикского или казахского языков, то выясняется, что их не просто недостаточно – их нет». Автор: Мария Арялина. Источник: www.vedomosti.ru
Пост взят с международного финтех-медиа ресурса
ДЛЯ ЛЮДЕЙ


![Аватар сообщества РУСАЛ [новости]](/uploads/community/4/c22a1b99-2a6d-4c64-82ea-cd56b3136042.jpg)

![Аватар сообщества ОЗОН [новости]](/uploads/community/4/d0f68b86-9cb8-4666-b03b-b569b9fd8e52.jpg)


![Аватар сообщества М.ВИДЕО [новости]](/uploads/community/4/10d22a5b-ae04-4983-9c4e-efd0dc8b55ea.jpg)

![Аватар сообщества САМОЛЕТ [новости]](/uploads/community/5/fbf34637-5b0e-4fd5-a2c9-90671cf38c49.jpg)

![Аватар сообщества СПБ БИРЖА [новости]](/uploads/community/4/0859b659-6649-436c-8190-6f5d8f46a243.jpg)
![Аватар сообщества АЭРОФЛОТ [новости]](/uploads/community/5/9c34a6c8-3c7d-4285-917c-b43d502647be.jpg)

![Аватар сообщества ПИК [новости]](/uploads/community/2/1712325580_70f20f445ea36b90e3c8f45498bd7113.jpg)



![Аватар сообщества ЛЕНТА [новости]](/uploads/community/4/7aae9c5f-8fb9-48d3-a6a7-ff9e0c2e34a6.jpg)
![Аватар сообщества АФК СИСТЕМА [новости]](/uploads/community/5/dbc4b2b4-8f18-4134-a0f0-07e7e15dc384.jpg)
![Аватар сообщества ЭСЭФАЙ [новости]](/uploads/community/3/1712481156_177350d5c60b503464917fd3185fbd05.jpg)
![Аватар сообщества ГАЗПРОМ НЕФТЬ [новости]](/uploads/community/4/1013fb93-41a0-457a-a9ac-772f2d38d37b.jpg)


![Аватар сообщества ОЗОН ФАРМА [новости]](/uploads/community/11/6c514de7-583c-4d32-b4db-33b837b522f0.jpg)

![Аватар сообщества САХАЛИН-Э [новости]](/uploads/community/6/a218c1d9-8909-42df-b618-d84cae29bdad.jpg)
![Аватар сообщества МТС [новости]](/uploads/community/2/3eb48c63-edb4-4484-a73d-0d3b20bc449c.jpg)

![Аватар сообщества УРАЛКУЗ [новости]](/uploads/community/7/28d65472-0a93-4a49-8da8-29b6f181949c.jpg)
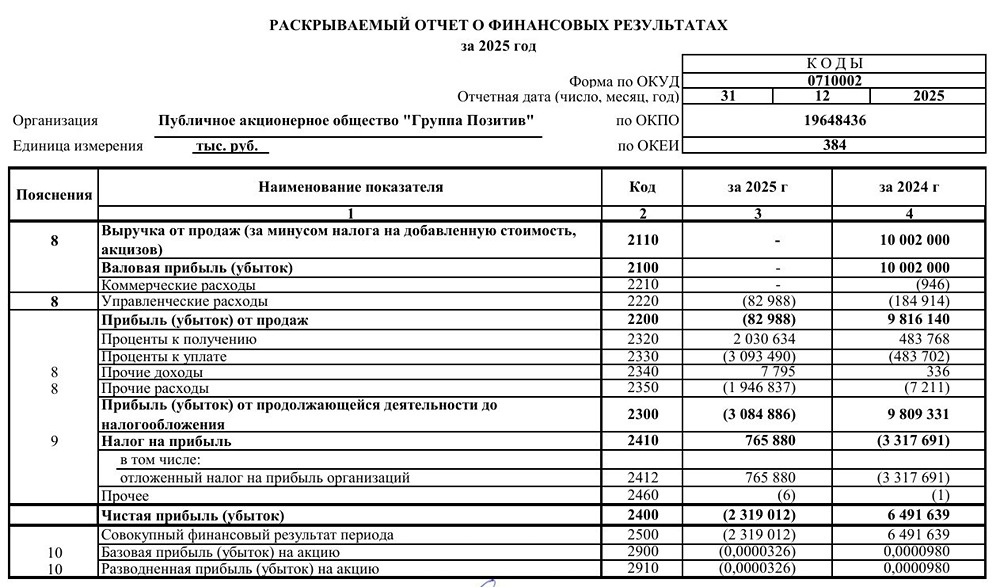
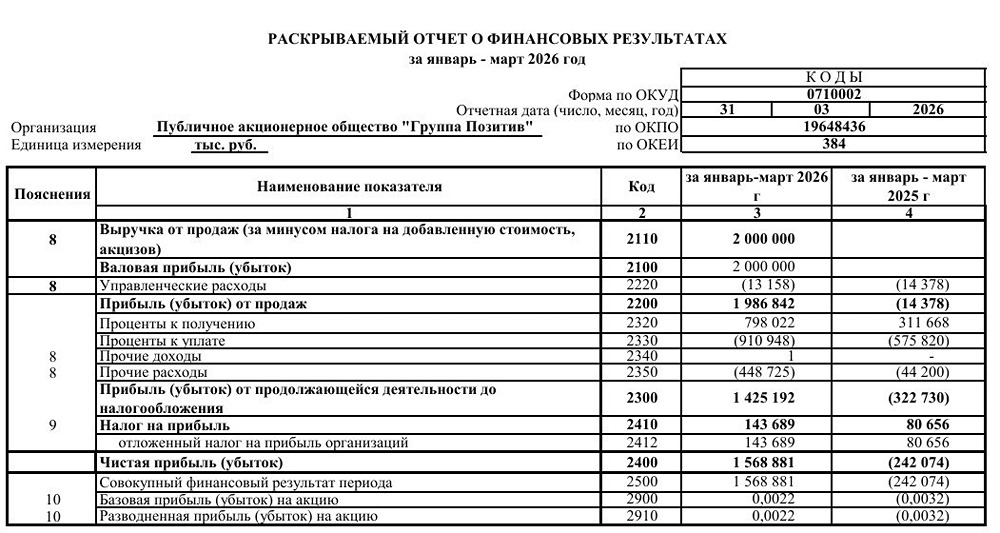
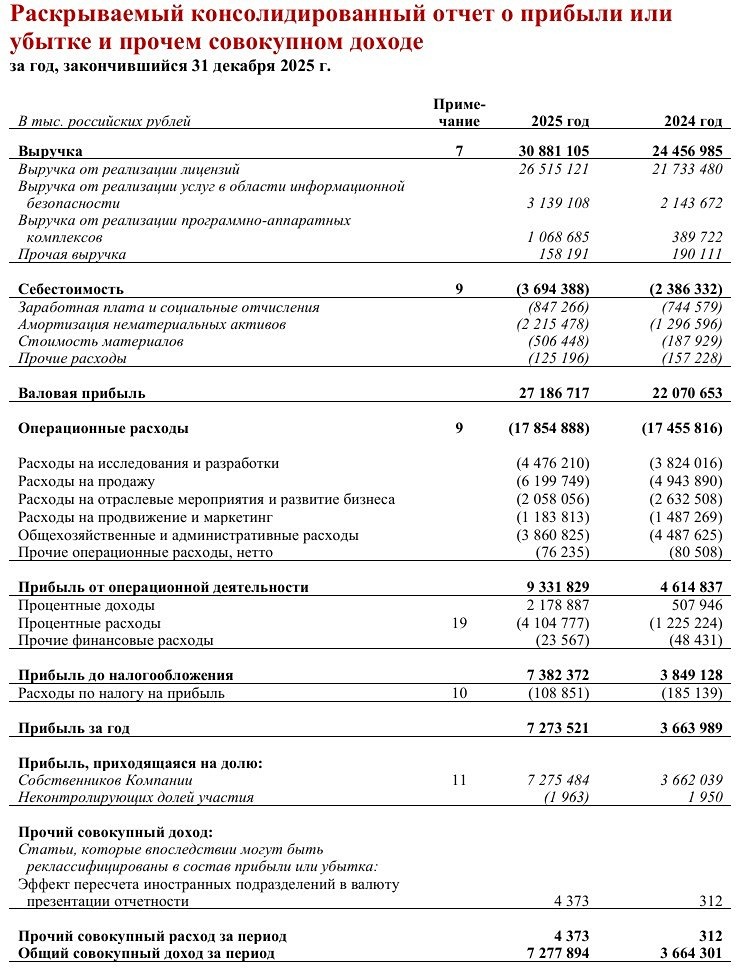
![Аватар сообщества ПОЗИТИВ [новости]](/uploads/community/6/1712605680_f2686d4814462e7121fcf08d8701b0e8.jpg)

![Аватар сообщества ФИКС ПРАЙС [новости]](/uploads/community/5/6498c024-6b0f-476f-82fa-67c4e29cff7f.jpg)
![Аватар сообщества ЧМК [новости]](/uploads/community/7/921c8575-ad22-47af-9ff1-84a4e3ffaa40.jpg)
![Аватар сообщества ДВМП [новости]](/uploads/community/7/213abd5c-8fe7-4d76-95e9-9c8993fd0785.jpg)
![Аватар сообщества ЕВРОТРАНС [новости]](/uploads/community/3/6e3a9678-3642-4433-9125-09e596c0b615.jpg)

![Аватар сообщества ТРАНСНЕФТЬ [новости]](/uploads/community/2/068fe35f-9411-4f55-ac84-ed989235d1e2.jpg)

![Аватар сообщества ГЛОРАКС [новости]](/uploads/community/12/f58e455a-21b3-409f-84d7-5b05581783ff.jpg)
![Аватар сообщества АСТРА [новости]](/uploads/community/6/6f45ba26-0adb-4531-9664-fc33f5b25c40.jpg)

![Аватар сообщества ЭТАЛОН [новости]](/uploads/community/6/7d25deae-ab4b-4ae5-9a09-bb3a459cea3f.jpg)
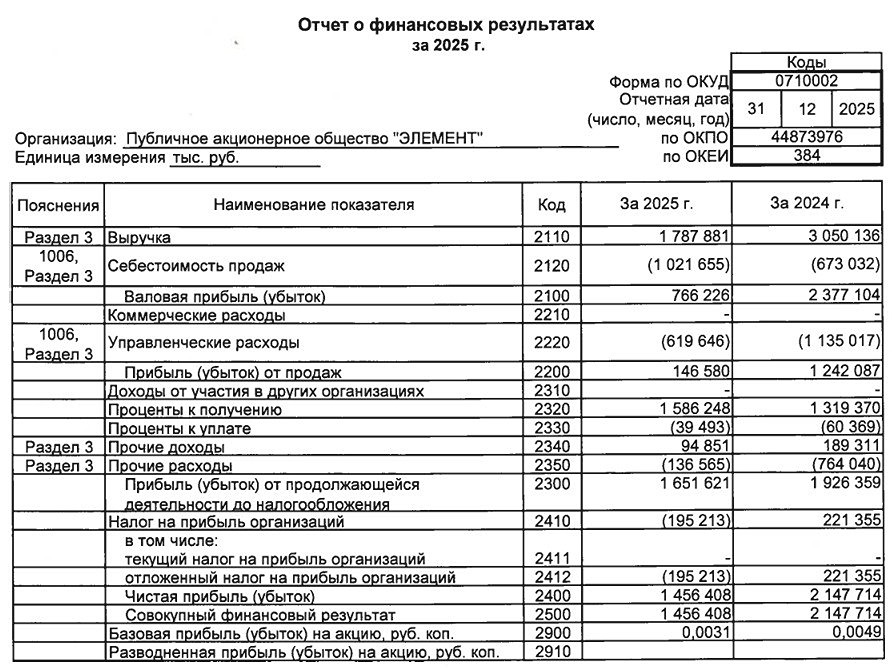
![Аватар сообщества ЭЛЕМЕНТ [новости]](/uploads/community/7/b73af150-0f81-4e23-9eba-752cd6df78d6.jpg)
![Аватар сообщества СОВКОМФЛОТ [новости]](/uploads/community/2/e3085cf2-7d8e-4952-a6af-7b6a0e26820c.jpg)


![Аватар сообщества ЛАМБУМИЗ [новости]](/uploads/community/11/95c88a09-2144-4cfc-a9d9-1d777a0683fa.jpg)
![Аватар сообщества ЧКПЗ [новости]](/uploads/community/1/1712247677_64a388c82527db160f33dadcd4389b1e.jpg)