![Аватар сообщества ЯНДЕКС [новости]](/uploads/community/2/dca78d58-9d3f-48a0-8d3a-7bf714273ff3.jpg)
Yambda — платформа для разработки рекомендательных систем: большие данные от Яндекса
Яндекс сделал доступным для всех Yambda — один из самых крупных в мире наборов данных для развития рекомендательных систем. Учёные, исследователи и вузы со всего мира теперь могут использовать Yambda для тестирования и улучшения рекомендательных алгоритмов. Yambda доступен в трёх вариантах: полная версия содержит 5 миллиардов данных, уменьшенные — 500 миллионов и 50 миллионов. Исследователи могут выбрать тот вариант, который лучше всего подходит для их задачи и имеющихся вычислительных ресурсов. Данные Yambda и код доступны на HuggingFace. Александр Плошкин, руководитель по развитию персонализации в Яндексе, отметил важность рекомендательных алгоритмов для поиска товаров, фильмов, музыки и других. Эти алгоритмы лежат в основе интернет-магазинов и онлайн-кинотеатров. Для развития алгоритмов нужны большие качественные данные. Опенсорс-наборы часто малы или устарели, так как компании редко их публикуют. Это создаёт разрыв между наукой и бизнесом. Большие открытые данные, такие как Yambda, решают эту проблему. Например, ImageNet дал толчок развитию компьютерного зрения. Yambda создан на основе данных Яндекс Музыки и включает агрегированные прослушивания, лайки, дизлайки и характеристики треков. Все данные анонимизированы, что обеспечивает конфиденциальность. Yambda подходит для оценки качества рекомендательных систем и привлекает молодых учёных. Источник: www.yandex.ru
Пост взят с международного финтех-медиа ресурса
ДЛЯ ЛЮДЕЙ
![Аватар сообщества ВТБ [новости]](/uploads/community/3/c12339dc-36d5-4ce9-ad90-344b2651ab58.jpg)

![Аватар сообщества СОВКОМБАНК [новости]](/uploads/community/4/56a71ff1-2cb3-4386-a4a6-0a4a40c531d0.jpg)

![Аватар сообщества ОЗОН [новости]](/uploads/community/4/d0f68b86-9cb8-4666-b03b-b569b9fd8e52.jpg)

![Аватар сообщества ПИК [новости]](/uploads/community/2/1712325580_70f20f445ea36b90e3c8f45498bd7113.jpg)



![Аватар сообщества РУСОЛОВО [новости]](/uploads/community/4/1712559811_6466d931d5c6c78220893babfe01e4fb.jpg)

![Аватар сообщества НОРНИКЕЛЬ [новости]](/uploads/community/1/4e8a1264-547a-4d74-b314-6b056dc5df9f.jpg)


![Аватар сообщества АЛРОСА [новости]](/uploads/community/5/a9bb43bd-ed64-426d-ac47-fa358b26c985.jpg)

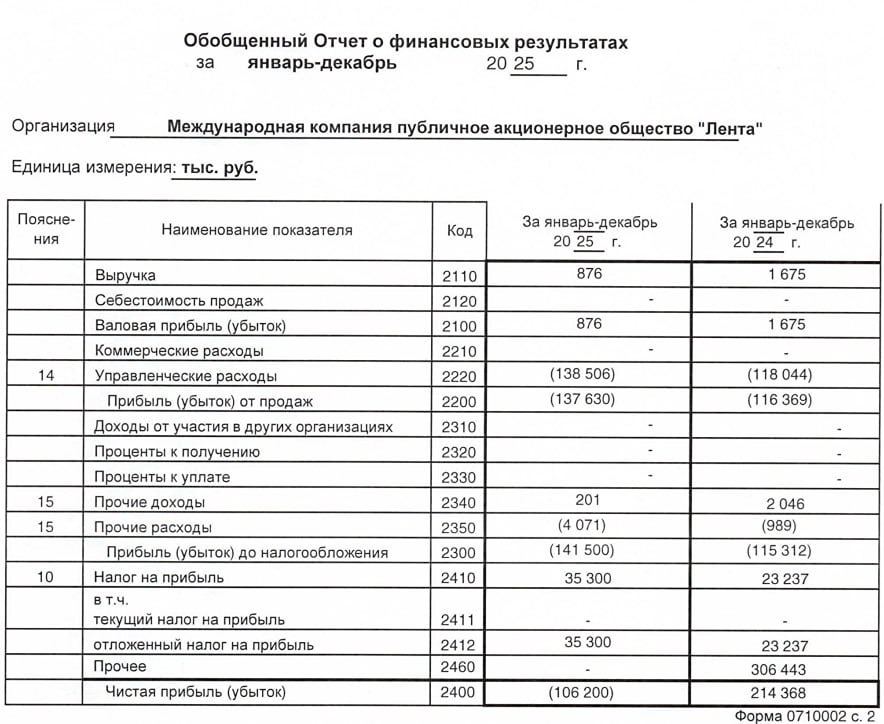
![Аватар сообщества ЛЕНТА [новости]](/uploads/community/4/7aae9c5f-8fb9-48d3-a6a7-ff9e0c2e34a6.jpg)

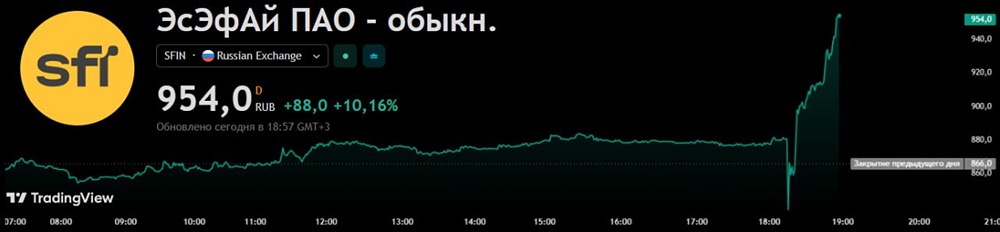
![Аватар сообщества ЭСЭФАЙ [новости]](/uploads/community/3/1712481156_177350d5c60b503464917fd3185fbd05.jpg)
![Аватар сообщества ГАЗПРОМ НЕФТЬ [новости]](/uploads/community/4/1013fb93-41a0-457a-a9ac-772f2d38d37b.jpg)



![Аватар сообщества АСТРА [новости]](/uploads/community/6/6f45ba26-0adb-4531-9664-fc33f5b25c40.jpg)


![Аватар сообщества ЕВРОТРАНС [новости]](/uploads/community/3/6e3a9678-3642-4433-9125-09e596c0b615.jpg)


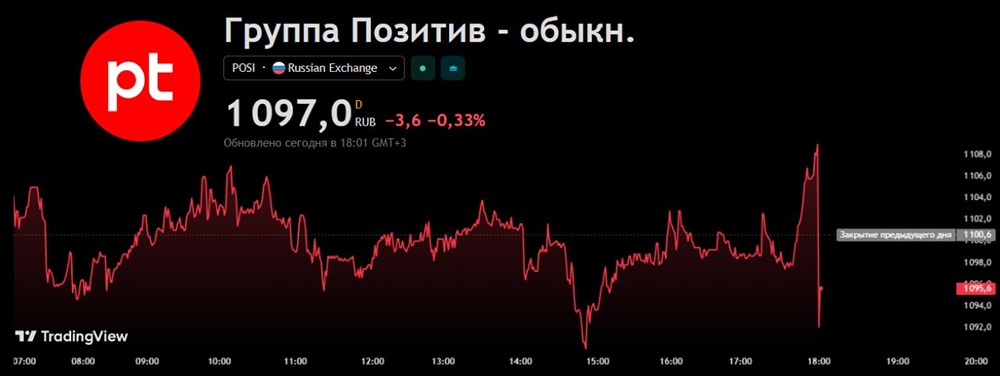
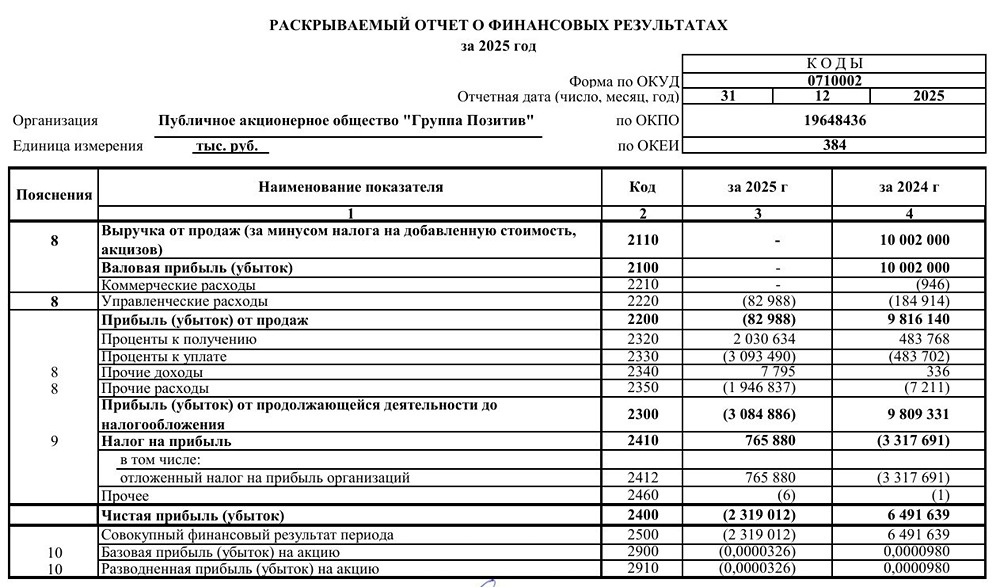
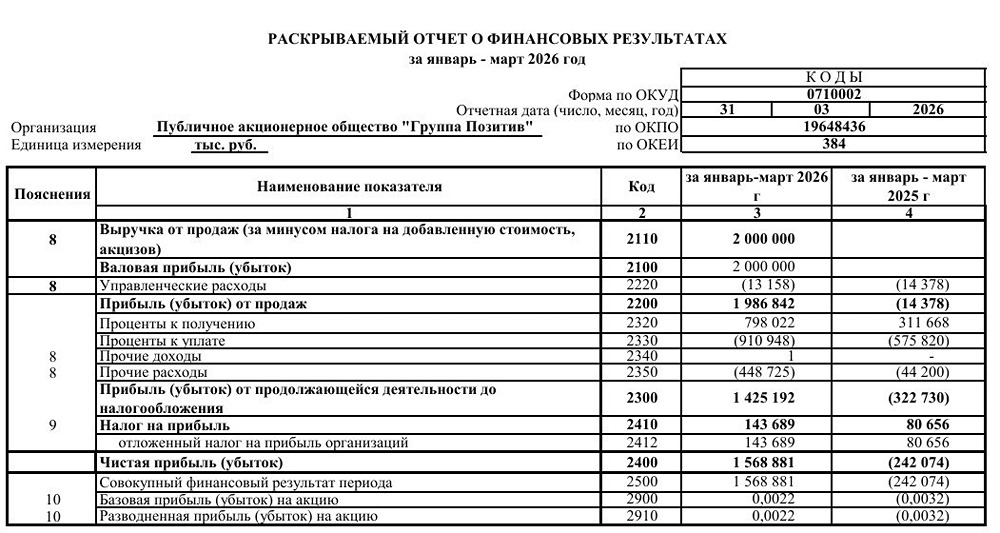
![Аватар сообщества ПОЗИТИВ [новости]](/uploads/community/6/1712605680_f2686d4814462e7121fcf08d8701b0e8.jpg)

![Аватар сообщества РУСАЛ [новости]](/uploads/community/4/c22a1b99-2a6d-4c64-82ea-cd56b3136042.jpg)

![Аватар сообщества РОСНЕФТЬ [новости]](/uploads/community/2/9b11fcbd-0311-4866-868b-e98ea726e426.jpg)

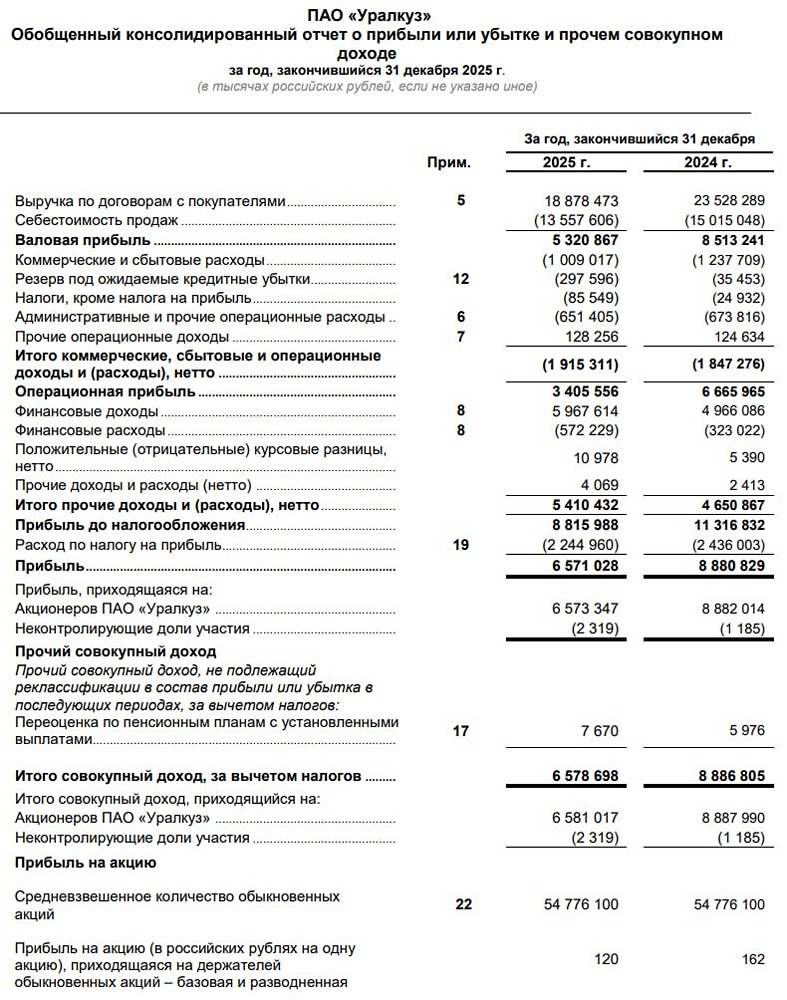
![Аватар сообщества УРАЛКУЗ [новости]](/uploads/community/7/28d65472-0a93-4a49-8da8-29b6f181949c.jpg)
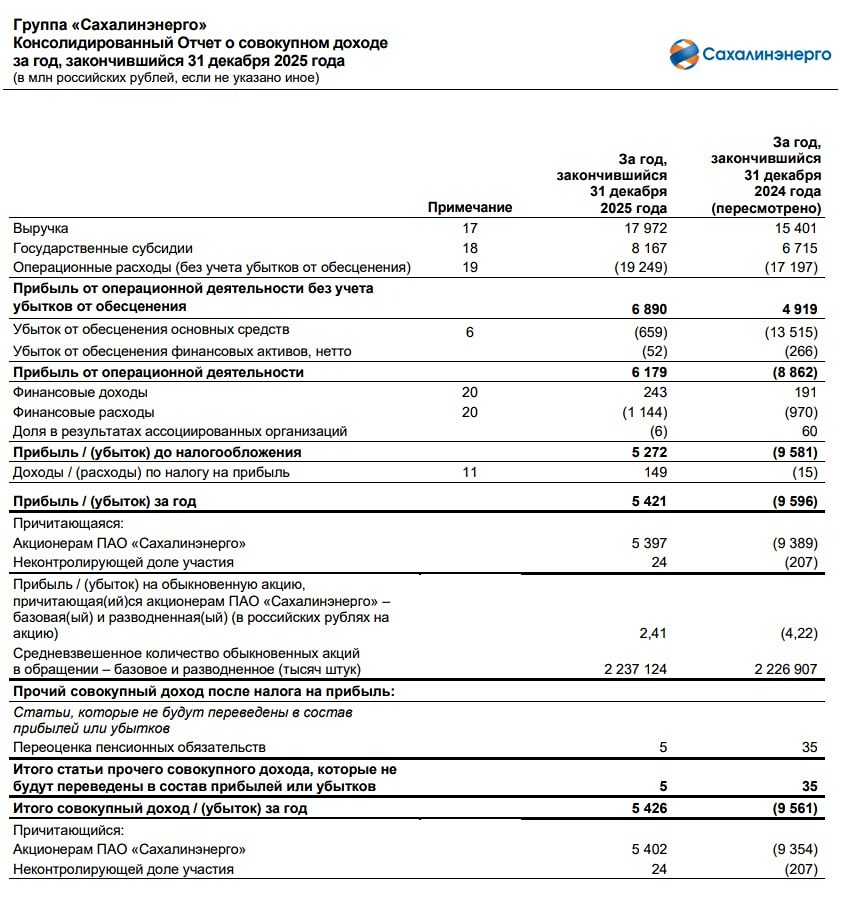
![Аватар сообщества САХАЛИН-Э [новости]](/uploads/community/6/a218c1d9-8909-42df-b618-d84cae29bdad.jpg)
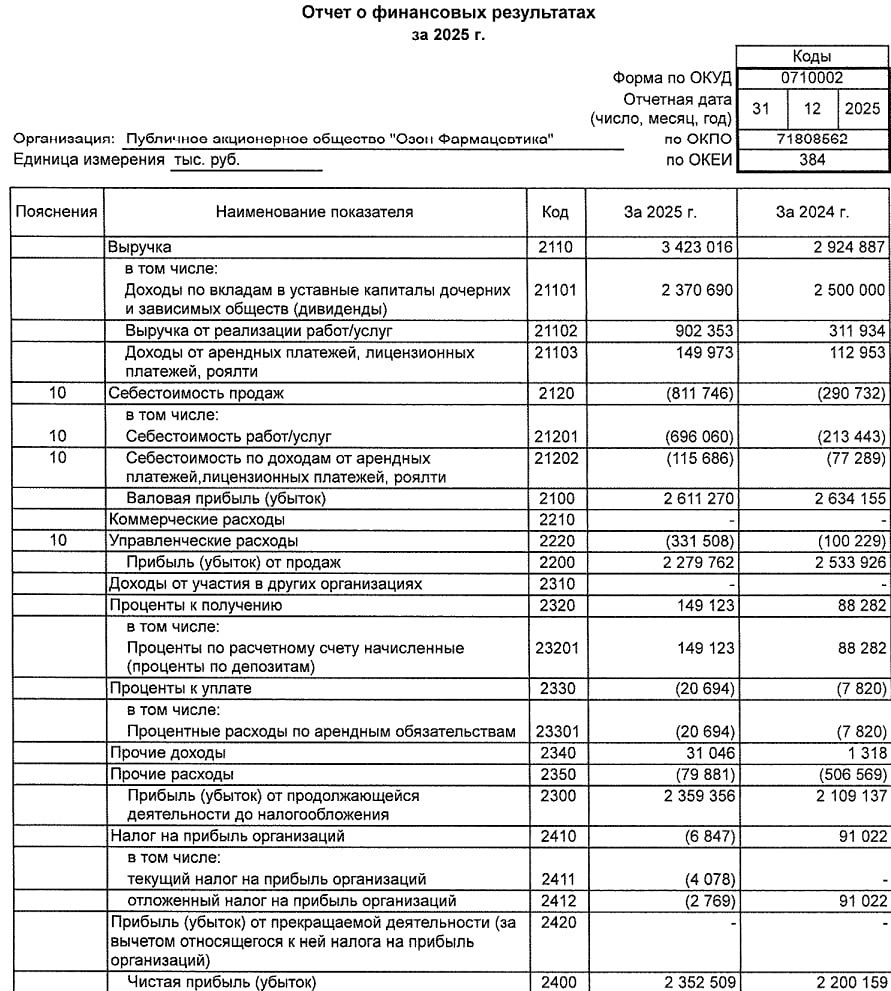
![Аватар сообщества ОЗОН ФАРМА [новости]](/uploads/community/11/6c514de7-583c-4d32-b4db-33b837b522f0.jpg)

![Аватар сообщества ДВМП [новости]](/uploads/community/7/213abd5c-8fe7-4d76-95e9-9c8993fd0785.jpg)
![Аватар сообщества САМОЛЕТ [новости]](/uploads/community/5/fbf34637-5b0e-4fd5-a2c9-90671cf38c49.jpg)


![Аватар сообщества Т-ТЕХНОЛОГИИ [новости]](/uploads/community/2/1712395803_348b41b8527715ec9b25c8a07bde2325.jpg)

![Аватар сообщества ЭТАЛОН [новости]](/uploads/community/6/7d25deae-ab4b-4ae5-9a09-bb3a459cea3f.jpg)

![Аватар сообщества АБРАУ-ДЮРСО [новости]](/uploads/community/4/1712559142_5c2519facd0c7c64fbd26e043807758a.jpg)

![Аватар сообщества КАМАЗ [новости]](/uploads/community/7/357c0a50-6818-4bf6-bb19-5cc2e0507547.jpg)

![Аватар сообщества B2B‑РТС [новости]](/uploads/community/12/fc33460c-3cef-454f-8924-f94a83478210.jpg)